Luke Macken caught me for a few minutes last weekend, after he had talked with Greg about skillset capturing. Luke wanted to talk about the join page work that Mo and I lead last year, and how to merge that with the idea of capturing skills of people when they join, then funneling directly to projects and specific tasks.
As it happens, when we did that Join page, we were thinking along very similar lines as to what Luke is looking for now, but being a designer and a content writer trying to get something done, we left the computation up to the joiner. That is, we gave them a list of projects and what skillsets were useful there, and left the figuring out where to go next to the individual joining. Crude, but a step forward. It’s great that the mental work we did back then can help inform a workflow tool now.
Luke is writing that computational part now, to take a skillset from the joiner and compare it with a list of projects and tasks within those projects. I think the best order to proceed is:
- Create a new workflow that captures skills, puts them in a database
- Use the current information we have in the Join page as a basis for the second part of that comparison
- Begin ASAP to use the intersection of those two sets to give back to joiners a specific list of active projects (not yet tasks), with a [details] and [join communications] link.
- Details goes to the [[ProjectName/Join]] page on the wiki
- Join communications goes, right now, to [[ProjectName/Join#Communications]]
- When we have a programmatically generated list of tasks ranked by community voting/karma, insert that into the decision tree as another set to find an intersection with
- Find a way to get a meaningful union of the sets of projects and tasks, then use that to intersect with the skills set?
This gets us changes within a few weeks that can make a real difference, while also kicking off a skills database that we can use continuously thereafter.
What website idea is complete without a diagram? Even better, it was scratched out on hotel notepaper while sitting at a pub later the same night as the discussion with Luke. This first pass compresses out the details of the decision matrix at the end:
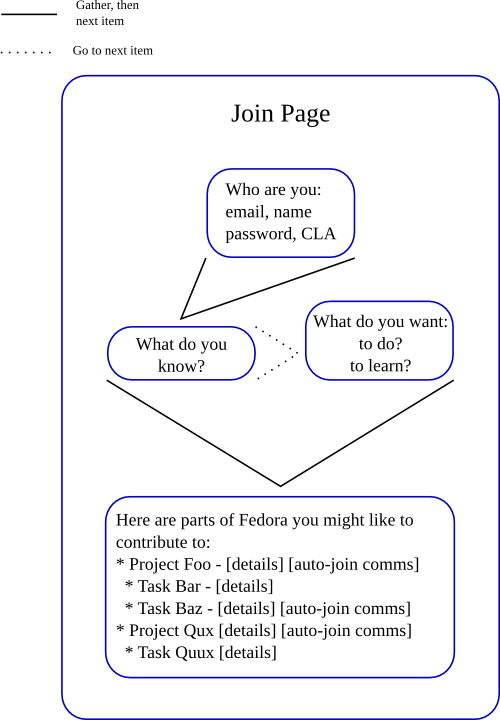
One thing to consider is that maybe we shouldn’t be pushing people to create an account and sign the CLA until they’ve found an avenue of contribution. It’ll help keep “dead” accounts out of the system and make it so that we have a more realistic idea of the size of our contributor base.
eg, right now, there are apparently like 4069 contributors in cla_done, but only 1750 of them are in any other group (based on # of accounts on fedorapeople)
I would strongly suggest avoiding the karma/voting system on the general desirability of a specific task. Do we really want drive new, pontentially underskilled contributors to a list of ideas ranked by general popularity (ranked by people who are not stepping forward to do the work), over suitability?
I have deep concerns over exposing any popularity ranking. I don’t think popularity is a proper motivation for sustainable contribution. I’d rather try to find a way to rank that helps a new person find a project that is most suited towards their skills, their experience, and their time constraints. General desirability of one task relative to another is not an important factor in matching a specific person to a well suited task.
As long as we know all the tasks in the list are desirable “enough” to show to potential contributors, we should not attempt to sort that list based on desirability.
-jef
One thing to consider. Doing ‘TurboGears’ does not mean I think in a certain way. I love to do web applications, but that does not mean I can pick up just any web application in the Fedora Infrastructure. What metric are you using to evaluate the newcomer’s coding style? How are you comparing this to the body of projects we have in Fedora? Is this really going to be effective in the long run?